 PIXIV: 71888962 @Yuuri
PIXIV: 71888962 @Yuuri
A little digression first
Langchain has recently updated a plethora of features, including Langsmith, Langgraph, LECL, and so on. I feel that the project is preparing to branch out, with one part heading towards a commercial version and another towards the community. The documentation is quite chaotic at the moment, and as of the end of January, there’s still plenty of room for improvement. In the future, I won’t introduce much about Langchain anymore, but I will mention it if I have any good ideas.
A Brief Discussion on TTS
TTS (Text To Speech) is a branch of speech synthesis that converts normal language text into speech. Here is a typical flowchart, which is just to show off…
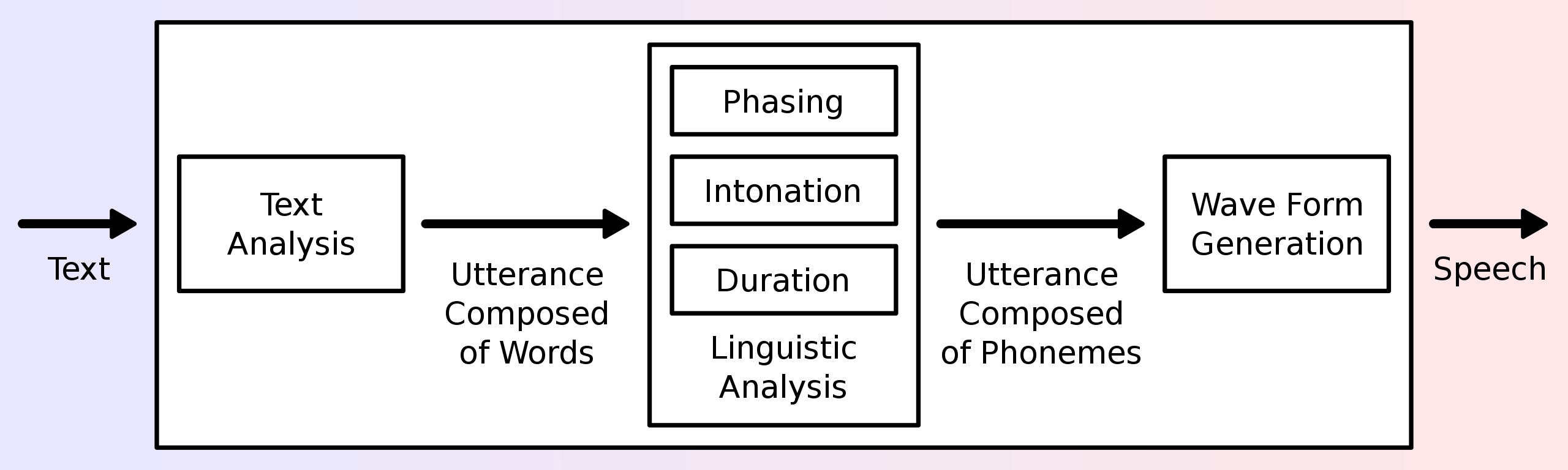
TTS systems are helpful for enhancing interactivity, and with recent technological advancements, TTS technology has flourished.
From RVC’s real-time voice changing and dynamic intonation optimization to the excellent effects of VITS, the addition of Generative Adversarial Networks (GAN) has made the voices much more natural compared to the past. With the powerful tone control capabilities of SO-VITS and the support of excellent datasets like Diff-SVC, the voices of virtual idols are comparable to real humans, but this also brings a series of problems… In my limited understanding, my knowledge of speech synthesis is still stuck in the era of Hatsune Miku. Yet, the pace of change is just that fast…
With such a thriving open-source community, the commercial sector is certainly not lagging behind. Looking at the commercial camp, each company has its own unique offerings. For example, Acapela Group specializes in TTS for deceased celebrities, which is quite distinctive. There are also many others, focusing on high-quality or emotionally rich TTS, customized voices, etc. But when it comes to the leader in the commercial TTS industry, it has to be Azure TTS. In this article, we will also use Microsoft’s free EdgeTTS service as an example.
Note that there are a lot of TTS engines on the internet now, and this article only uses the relatively stable Edge-TTS, with the initial intention for practical application. If you need to use TTS entirely locally or for fun, personalized training of voices and special models, this tutorial is not suitable. Please move to other personalized TTS alchemy tutorials, such as GPT-SO-VITS, etc.
Edge TTS
TTS accepts text input and then outputs audio. For the Python version of Edge TTS, it actually still makes network requests. So it can work well on edge computing platforms because the audio synthesis is actually computed in the cloud and returned to you. We are using the Edge TTS Python library, and here is the GitHub project URL: edge-tts.
Installing Edge TTS
First, we install it:
pip install edge-tts
Edge TTS has two modes of operation, one is using the command line interaction, if you just want to use the command mode, you can install it with pipx (from the official verbose tutorial):
pipx install edge-tts
We will skip the command line mode here.
Using Edge TTS
First, create an Edgetts.py file, then we import the required modules
# Import the necessary libraries
import asyncio
import edge_tts
import os
Then we first initialize the TTS engine.
For the options of language and voice, to ensure accuracy, we first enter the command in the command line window to get the supported list:
edge-tts --list-voices
You will find that a big list is outputted, which I won’t post here. Choose the NAME you need and then we continue to write the initialization code:
# Set the text to be converted to speech
TEXT = "Hello, this is lico! Welcome to lico's metaverse!"
# Set the language and voice of the speech, I chose Xiaoyi for testing here, note that this name is case sensitive
VOICE = "zh-CN-XiaoyiNeural"
# Set the path of the output file, the file will be saved in the folder where the script is located
OUTPUT_FILE = os.path.join(os.path.dirname(os.path.realpath(__file__)), "test.mp3")
Alright, we use the edgetts function to generate the speech. Note that it runs asynchronously:
# Define the main function
async def _main() -> None:
# Create a Communicate object to convert text into speech
communicate = edge_tts.Communicate(TEXT, VOICE)
# Save the speech to a file
await communicate.save(OUTPUT_FILE)
Finally, we add the main function, and the overall code should look like this:
# Import the necessary libraries
import asyncio
import edge_tts
import os
# Set the text to be converted to speech
TEXT = "Hello, this is lico! Welcome to lico's metaverse!"
# Set the language and voice of the speech
VOICE = "zh-CN-XiaoyiNeural"
# Set the path of the output file, the file will be saved in the folder where the script is located
OUTPUT_FILE = os.path.join(os.path.dirname(os.path.realpath(__file__)), "test.mp3")
# Define the main function
async def _main() -> None:
# Create a Communicate object to convert text into speech
communicate = edge_tts.Communicate(TEXT, VOICE)
# Save the speech to a file
await communicate.save(OUTPUT_FILE)
# If this script is run directly, rather than being imported, then run the main function
if __name__ == "__main__":
asyncio.run(_main())
After running it from the command line, you will find that a test.mp3 has been generated next to the script, which is the generated speech. You can try to play it without socially dying or change it to a more socially fatal text.
Edge TTS also offers the option of streaming generation, which I won’t elaborate on here, because streaming only refers to the output, and input cannot be streamed, as it requires planning the intonation and phonemes for the entire text. However, we still have the opportunity to solve this problem, and I will write about it when the opportunity arises.
# Official example of streaming generation
async def amain() -> None:
"""Main function"""
communicate = edge_tts.Communicate(TEXT, VOICE)
with open(OUTPUT_FILE, "wb") as file:
async for chunk in communicate.stream():
if chunk["type"] == "audio":
file.write(chunk["data"])
elif chunk["type"] == "WordBoundary":
print(f"WordBoundary: {chunk}")
Combining LLM with TTS
Next, we will try to add TTS voice output to our last code. But before that, we need to modify our TTS script a bit to turn it into a function so that we can call it when needed.
I want to use command line interaction and be able to play sound. Considering cross-platform compatibility, we install a library pip install pyaudio:
pip install pyaudio
Then we modify the previous script to see if we can play it:
# Import the necessary libraries
import asyncio
import edge_tts
import os
import pyaudio
import wave
# Set the text to be converted to speech
TEXT = "Hello, this is lico! Welcome to lico's metaverse!"
# Set the language and voice of the speech
VOICE = "zh-CN-XiaoyiNeural"
# Set the path of the output file, the file will be saved in the folder where the script is located
OUTPUT_FILE = os.path.join(os.path.dirname(os.path.realpath(__file__)), "test.wav")
# Define the main function
async def _main() -> None:
# Create a Communicate object to convert text into speech
communicate = edge_tts.Communicate(TEXT, VOICE)
# Save the speech to a file
await communicate.save(OUTPUT_FILE)
# Open the audio file
wf = wave.open(OUTPUT_FILE, 'rb')
# Initialize pyaudio
p = pyaudio.PyAudio()
# Open the audio stream
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
# Read and play the audio file
data = wf.readframes(1024)
while len(data) > 0:
stream.write(data)
data = wf.readframes(1024)
# Stop the audio stream
stream.stop_stream()
stream.close()
# Terminate pyaudio
p.terminate()
# If this script is run directly, rather than being imported, then run the main function
if __name__ == "__main__":
asyncio.run(_main())
(I haven’t finished writing, I will continue when I have time)